CAPE - the "ikigai" of buiness onboarding
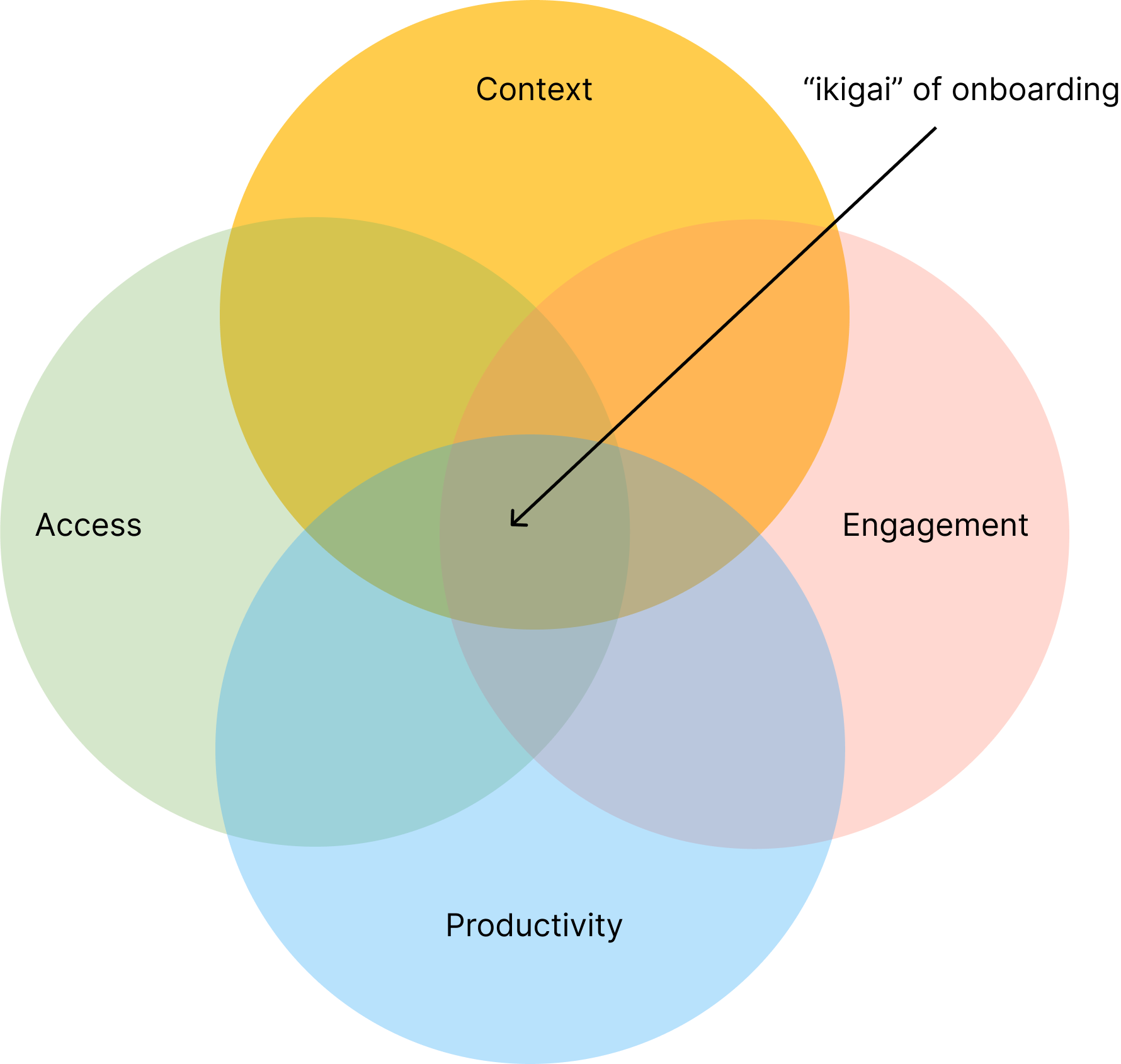
The Japanese philosophy of Ikigai embodies the idea of discovering purpose, meaning, and fulfillment in life. It is frequently characterized as the convergence of four elements: passion, competence, societal need, and financial viability. When we...
18 Sep 2023







