
This post demonstrates the mathematical model behind logistic regression, which serves as the building block of the deep learning. I write this post to help others understand deep learning, I also write it for myself to learn deep learning more deeply.
Model after biological neuron
Modern deep learning techniques model after biological cognition, the basic unit of which is neuron. It is the building block of deep learning starts with neuron-inspired math modeling using logistic regression. The math behind a simple logistic regression classifier looks like below:
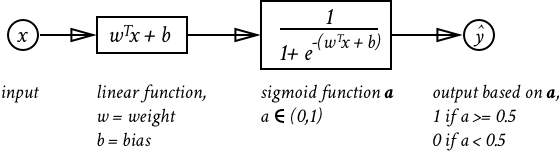
Image this function represents a neuron in your brain, the input is the stimulus your brain received (sound, touch, etc.), represented by the data captured in ; and the output is a binary decision of whether that neuron gets triggered or not, represented by the binary value of .
In order to have the neuron work properly, we need to have decent value for weights and bias terms, denoted as and respectively. However, we don’t have good values for nor automatically, we need to train our model and acquire good weights and bias terms. Image our function as a newborn baby, and it takes training to teach a baby to walk, speak etc. We need to train our neuron model and figure out good values for and .
So the question is how to train for logistic regression? Given we have a set of training dataset, we can measure the error of our current model by comparing predicted value and actual value, then take the result to do better. We can break down the question of how to train for logistic regression into a set of smaller problems:
- question 1: how to define the error of predictions from our model?
- question 2: how to take the error to refine our model?
The technique to address question 1 is called forward propagation, and the technique to address question 2 is called backward progation.
Forward Propagation
Forward progation enables two things. First, it provides a predicted value based on the input . To break down the calculation mathematically:
If the value of is greater than or equal to 0.5, then is predicted as 1, otherwise is 0.
Second, it allows the model to calculate an error based on a loss function, this error quantifies how well our current model is performing using and . The loss function for the logistic regression is below:
How does this loss function makes sense? The way I think about is that if the prediction is close to actual value, the value should be low. If the prediction is far from actual value, the value should be high. Gi
cost function based on loss function
Next we define a cost function for the entire dataset based on the loss function because we have many rows of training data, say records. The value of the error based on the cost function is avaraged out across all errors:
Given we have a way to measure the error of our prediction model, we can set the goal to minimize prediction error by adjusting our model parameters, and this is where backward propagation comes in.
Backward Propagation
To tackle the problem of how to refine our model to reduce training error, we can more formally define our problem as following:
- Given a dataset
- The model computes
- The model calculates the cost function:
- Apply cost function to adjust and
To implement step 4, we need to apply gradient descent.
Gradient Descent
Quote from Wikipedia on gradient descent:
Gradient descent is a first-order iterative optimization alogirthm for finding the minimum of a function.
Great! We want to find the minimum of our cost function by adjusting and . Following the gradient descent algorithm, we take the following steps:
- taking partial derivatives off our parameters, which tells us the delta values of adjusting that value
- update our parameters based on the delta value from the partial derivatives

The goal is to learn and by minimizing the cost function . For a parameter , the update rule is , where is the learning rate.
Translate the steps above mathematically, we get:
update w
update b
Put it all togher
We can now have a big picture of how we want to use logistic regression classifier to predict future dataset based on training dataset. A high-level architectural steps can be summarized as:
- Gather training dataset and test dataset .
- Initialize model parameters and .
- Define learning rate , and number of training iterations.
- For each training iteration, run through:
- apply forward propagation with , and
- calculate cost funtion
- apply backward propagation to adjust and
- Verify the accuracy of the model using